之前做過一個每天訪問量達(dá)到800w的系統(tǒng),簡單說下自己的見解!
從整個應(yīng)用系統(tǒng)來看,想要支持超高并發(fā)量,負(fù)載均衡,緩存,消息中間件,數(shù)據(jù)庫讀寫分離,分庫分表等必不可少,既然文章只問了數(shù)據(jù)庫系統(tǒng),那就只談數(shù)據(jù)庫!
數(shù)據(jù)庫層面,一般無外乎是主從復(fù)制,讀寫分離,分庫分表這些東西!
1,從單臺數(shù)據(jù)庫性能來看,單個mysql實(shí)例最大連接數(shù)為16384,就是說在同一時間最多能容納那么多的訪問量,同時受服務(wù)器CPU,內(nèi)存,硬盤等的影響,但是在實(shí)際應(yīng)用中能達(dá)到2000就不錯了!
需要使用druid等數(shù)據(jù)庫監(jiān)控中間件,實(shí)時的監(jiān)控數(shù)據(jù)庫連接,sql效率等各種指標(biāo),在達(dá)到瓶頸之前找到辦法,show status;這個指令也可以方便的查看數(shù)據(jù)庫實(shí)例的各項(xiàng)指標(biāo)
單臺數(shù)據(jù)庫實(shí)例配置最優(yōu)化是保證整個數(shù)據(jù)庫集群最優(yōu)化的基本保證!
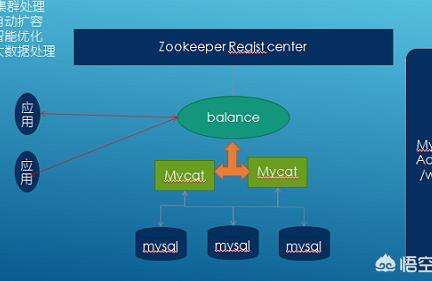
2,數(shù)據(jù)庫集群:以分庫分表為例,分庫分表的方式有很多,比如mycat,Sharding-jdbc等。
分庫分表的思想很簡單,比如單表1億的數(shù)據(jù)量,查詢效率很低,如果使用8庫1024表拆分,每張表中的數(shù)據(jù)不會超過10萬,對數(shù)據(jù)庫來說不存在任何瓶頸,就算總數(shù)據(jù)量達(dá)到100億,單表的查詢也不會慢!
拆分的策略通常以某個全局唯一的業(yè)務(wù)主鍵使用某種方式(比如hash取模,按月份等等)進(jìn)行分庫分表的計(jì)算!
那么問題來了,全局唯一的字段怎么獲取?普通的數(shù)據(jù)庫主鍵自增,uuid等不再合適,可以使用redis,zookeeper等獲取全局唯一的id,具體可參見之前的其他回答!
問題:分庫分表之后存在跨庫join的問題,通常的解決方式為1,盡量使用分庫分表主鍵能保證在同一庫,同一類型的表中進(jìn)行連接查詢,2,增加專門的查詢庫:將常用的數(shù)據(jù)字段冗余到查詢庫中,方便連接查詢和常用字段的快速查詢;
4,sql優(yōu)化:最基本的條件查詢,count,分組等使用索引字段等避免全局查詢,避免null值判斷,避免使用not in,避免無效的like語句,避免查詢的時候使用函數(shù)操作等等!
5,像秒殺系統(tǒng)等這種瞬時高并發(fā),最好借助緩存系統(tǒng)來完成!
總而言之,數(shù)據(jù)庫是整個應(yīng)用系統(tǒng)當(dāng)中最核心,也是最容易出問題的地方,做好監(jiān)控,提前預(yù)防才能保證系統(tǒng)訪問量的增長!